
User's Manual
|
|
| Rabbit 2000 Microprocessor User's Manual |
|
3. Details on Rabbit
Microprocessor Features3.1 Processor Registers
The Rabbit's registers are nearly identical to those of the Z180 or the Z80. The figure below shows the register layout. The XPC and IP registers are new. The EIR register is the same as the Z80 I register, and is used to point to a table of interrupt vectors for the externally generated interrupts. The IIR register occupies the same logical position in the instruction set as the Z80 R register, but its function is to point to an interrupt vector table for internally generated interrupts.
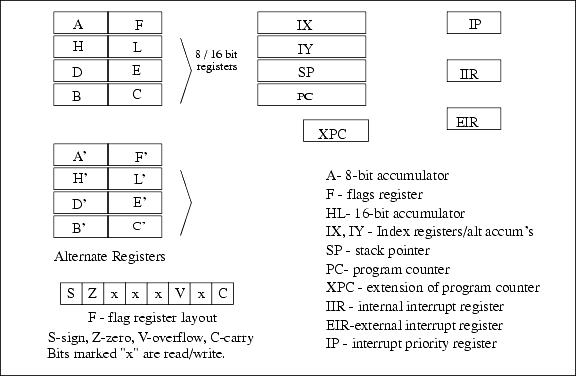
The Rabbit (and the Z80/Z180) processor has two accumulators--the A register serves as an 8-bit accumulator for 8-bit operations such as ADD or and. The 16-bit register HL register serves as an accumulator for 16-bit operations such as ADD HL,DE, which adds the 16-bit register DE to the 16-bit accumulator HL. For many operations IX or IY can substitute for HL as accumulators.
The register marked F is the flags register or status register. It holds a number of flags that provide information about the last operation performed. The flag register cannot be accessed directly except by using the POP AF and PUSH AF instructions. Normally the flags are tested by conditional jump instructions. The flags are set to mark the results of arithmetic and logic operations according to rules that are specified for each instruction. There are four unused read/write bits in the flag register that are available to the user via the PUSH AF and POP AF instructions. These bits should be used with caution since new-generation Rabbit processors could use these bits for new purposes.
The registers IX, IY and HL can also serve as index registers. They point to memory addresses from which data bits are fetched or stored. Although the Rabbit can address a megabyte or more of memory, the index registers can only directly address 64K of memory (except for certain extended addressing LDP instructions). The addressing range is expanded by means of the memory mapping hardware (see "Memory Mapping" on page 15) and by special instructions. For most embedded applications, 64K of data memory (as opposed to code memory) is sufficient. The Rabbit can efficiently handle a megabyte of code space.
The register SP points to the stack that is used for subroutine and interrupt linkage as well as general-purpose storage.
A feature of the Rabbit (and the Z80/Z180) is the alternate register set. Two special instructions swap the alternate registers with the regular registers. The instruction
EX AF,AF'exchanges the contents of AF with AF'. The instruction EXX exchanges HL, DE, and BC with HL', DE', and BC'. Communication between the regular and alternate register set in the original Z80 architecture was difficult because the exchange instructions provided the only means of communication between the regular and alternate register sets. The Rabbit has new instructions that greatly improve communication between the regular and alternate register set. This effectively doubles the number of registers that are easily available for the programmer's use. It is not intended that the alternate register set be used to provide a separate set of registers for an interrupt routine, and Dynamic C does not support this usage because it uses both registers sets freely.The IP register is the interrupt priority register. It contains four 2-bit fields that hold a history of the processor's interrupt priority. The Rabbit supports four levels of processor priority, something that exists only in a very restricted form in the Z80 or Z180.
3.2 Memory Mapping
Except for a handful of special instructions (see Section 18.5, "16-bit Load and Store 20-bit Address"), the Rabbit instructions directly address a 64K data memory space. This means that the address fields in the instructions are 16 bits long and that the registers that may be used as pointers to memory addresses (index registers (IX, IY), program counter and stack pointer (SP)) are also 16 bits long.
Because Rabbit instructions use 16-bit addresses, the instructions are shorter and can execute much faster than, for example, 32-bit addresses. The executable code is also very compact. Even though these 16-bit addresses are a valuable asset, they do create some complications because a memory-mapping unit is needed in order to access a reasonable amount of memory for modern C programs.
The Rabbit memory-mapping unit is similar to, but more powerful than, the Z180 memory-mapping unit. Figure 3-2 illustrates the relationship among the major components related to addressing memory.
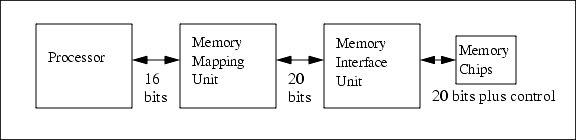
The memory-mapping unit receives 16-bit addresses as input and outputs 20-bit addresses. The processor (except for certain LDP instructions) sees only a 16-bit address space. That is, it sees 65536 distinctly addressable bytes that its instructions can manipulate. Three segment registers are used to map this 16-bit space into a 1-megabyte space. The 16-bit space is divided into four separate zones. Each zone, except the first or root zone, has a segment register that is added to the 16-bit address within the zone to create a 20-bit address. The segment register has eight bits and those eight bits are added to the upper four bits of the 16-bit address, creating a 20-bit address. Thus, each separate zone in the 16-bit memory becomes a window to a segment of memory in the 20-bit address space. The relative size of the four segments in the 16-bit space is controlled by the SEGSIZE register. This is an 8-bit register that contains two 4-bit registers. This controls the boundary between the first and the second segment and the boundary between the second and the third segment. The location of the two movable segment boundaries is determined by a 4-bit value that specifies the upper four bits of the address where the boundary is located. These relationships are illustrated in Figure 3-3.
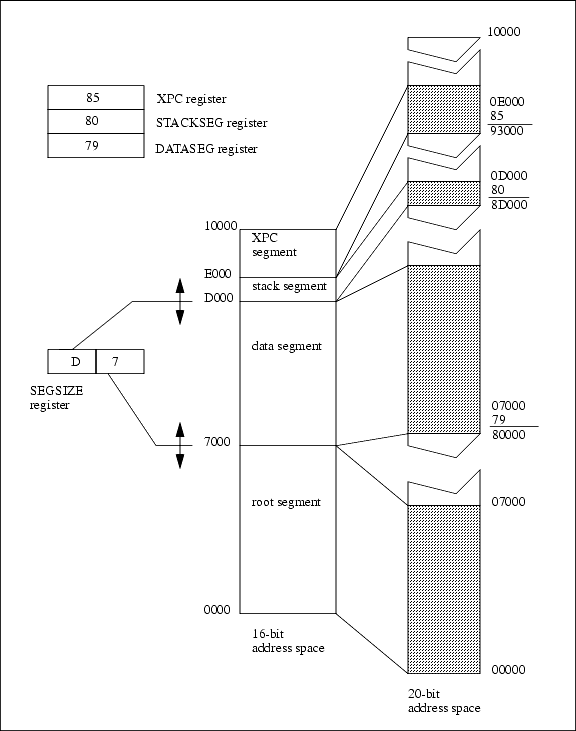
The names given to the segments in the figure are evocative of the common uses for each segment. The root segment is mapped to the base of flash memory and contains the startup code as well as other code that may happen to be stored there. The data segment usage varies depending on the overall strategy for setting up memory. It may be an extension of the root segment or it may contain data variables. The stack segment is normally 4K long and it holds the system stack. The XPC segment is normally used to execute code that is not stored in the root segment or the data segment. Special instructions support executing code that is visible in the XPC segment.
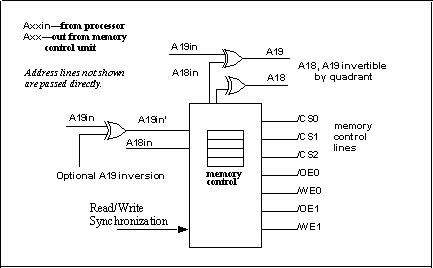
The memory interface unit receives the 20-bit addresses generated by the memory-mapping unit. The memory interface unit conditionally modifies address lines A16, A18 and A19. The other address lines of the 20-bit address are passed unconditionally. The memory interface unit provides control signals for external memory chips. These interface signals are chip selects (/CS0, /CS1, /CS2), output enables (/OE0, /OE1), and write enables (/WE0, /WE1). These signals correspond to the normal control lines found on static memory chips (chip select or /CS, output enable or /OE, and write enable or /WE). In order to generate these memory control signals, the 20-bit address space is divided into four quadrants of 256K each. A bank control register for each quadrant determines which of the chip selects and which pair of output enables, and write enables (if any) is enabled when a memory read or write to that quadrant takes place. For example, if a 512K x 8 flash memory is to be accessed in the first 512K of the 20-bit address space, then /CS0, /WE0, /OE0 could be enabled in both quadrants.
Figure 3-4 shows a memory interface unit.
3.2.1 Extended Code Space
A crucial element of the Rabbit memory mapping scheme is the ability to execute programs containing up to a megabyte of code in an efficient manner. This ability is absent in a pure 16-bit address processor, and it is poorly supported by the Z180 through its memory mapping unit. On paged processors, such as the 8086, this capability is provided by paging the code space so that the code is stored in many separate pages. On the 8086 the page size is 64K, so all the code within a given page is accessible using 16-bit addressing for jumps, calls and returns. When paging is used, a separate register (CS on the 8086) is used to determine where the active page currently resides in the total memory space. Special instructions make it possible to jump, call or return from one page to another. These special instructions are called long calls, long jumps and long returns to distinguish them from the same operations that only operate on 16-bit variables.
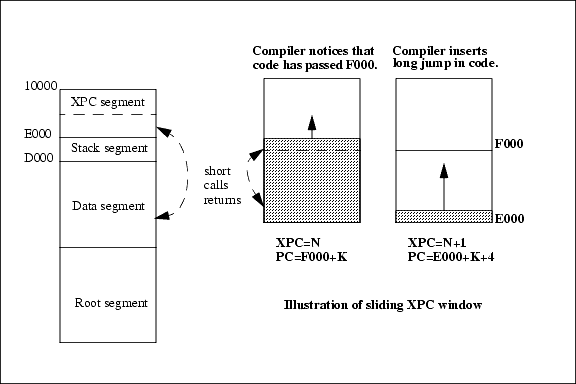
The Rabbit also uses a paging scheme to expand the code space beyond the reach of a 16-bit address. The Rabbit paging scheme uses the concept of a sliding page, which is 8K long. This is the XPC segment. The 8-bit XPC register serves as a page register to specify the part of memory where the window points. When a program is executed in the XPC segment, normal 16-bit jumps, calls and returns are used for most jumps within the window. Normal 16-bit jumps, calls and returns may also be used to access code in the other three segments in the 16-bit address space. If a transfer of control to code outside the window is required, then a long jump, long call or long return is used. These instructions modify both the program counter (PC) and the XPC register, causing the XPC window to point to a different part of memory where the target of the long jump, call or return is located. The XPC segment is always 8K long. The granularity with which the XPC segment can be positioned in memory is 4K. Because the window can be slid by one-half of its size, it is possible to compile continuously without unused gaps in memory.
As the compiler generates code resident in the XPC window, the window is slid down by 4K when the code goes beyond F000. This is accomplished by a long jump that repositions the window 4K lower. This is illustrated by Figure 3-5. The compiler is not presented with a sharp boundary at the end of the page because the window does not run out of space when code passes F000 unless 4K more of code is added before the window is slid down. All code compiled for the XPC window has a 24-bit address consisting of the 8-bit XPC and the 16-bit address. Short jumps and calls can be used, provided that the source and target instructions both have the same XPC address. Generally this means that each instruction belongs to a window that is approximately 4K long and has a 16-bit address between E000+n and F000+m, where n and m are on the order of a few dozen bytes, but can be up to 4096 bytes in length. Since the window is limited to no more than 8K, the compiler is unable to compile a single expression that requires more than 8K or so of code space. This is not a practical consideration since expressions longer than a few hundred bytes are in the nature of stunts rather than practical programs.
Program code can reside in the root segment or the XPC segment. Program code may also be resident in the data segment. Code can be executed in the stack segment, but this is usually restricted to special situations. Code in the root, meaning any of the segments other than the XPC segment, can call other code in the root using short jumps and calls. Code in the XPC segment can also call code in the root using short jumps and calls. However, a long call must be used when code in the XPC segment is called. Functions located in the root have an efficiency advantage because a long call and a long return require 32 clocks to execute, but a short call and a short return require only 20 clocks to execute. The difference is small, but significant for short subroutines.
3.2.2 Extending Data Memory
In the normal memory model, the data space must share a 64K space with root code, the stack, and the XPC window. Typically, this leaves a potential data space of 40K or less. The XPC requires 8K, the stack requires 4K, and most systems will require at least 12K of root code. This amount of data space is more than sufficient for most embedded applications.
One approach to getting more data space is to place data in RAM or in flash memory that is not mapped into the 64K space, and then access this data using function calls or in assembly language using the LDP instructions that can access memory using a 20-bit address. This is satisfactory for accessing simple data structures or buffers.
Another approach to extending data memory is to use the stack segment to access data, placing the stack in the data segment so as to free up the stack segment. This approach works well for a software system that uses data groupings that are self-contained and are accessed one at a time rather than randomly between all the groupings. An example would be the software structures associated with a TCP/IP communication protocol connection where the same code accesses the data structures associated with each connection in a pattern determined by the traffic on each connection.
The advantage of this approach is that normal C data access techniques, such as 16-bit pointers, may be used. The stack segment register has to be modified to bring the data structure into view in the stack segment before operations are performed on a particular data structure. Since the stack has to be moved into the data area, it is important that the number of stacks required be kept to a minimum when using the stack segment to view data. Of course, tasks that don't need to see the data structures can have their stack located in the stack segment. Another possibility is to have a data structure and a stack located together in the stack segment, and to use a different stack segment for different tasks, each task having its own data area and stack bound to it.
These approaches are shown in Figure 3-6 below.
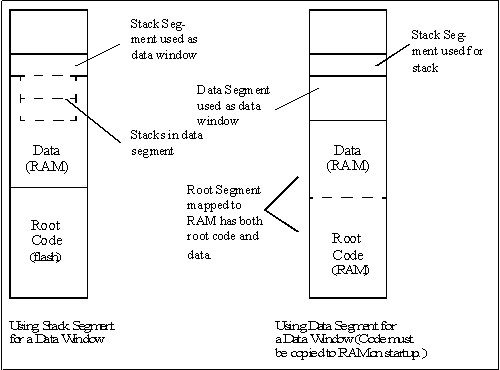
A third approach is to place the data and root code in RAM in the root segment, freeing the data segment to be a window to extended memory. This requires copying the root code to RAM at startup time. Copying root code to RAM is not necessarily that burdensome since the amount of RAM required can be quite small, say 12K for example.
The XPC segment at the top of the memory can also be used as a data segment by programs that are compiled into root memory. This is handy for small programs that need to access a lot of data.
3.2.3 Practical Memory Considerations
The simplest Rabbit configurations have one flash memory chip interfaced using /CS0 and one RAM memory chip interfaced using /CS1. Typical Rabbit-based systems use 256K of flash and 128 K of RAM, but smaller or larger memories may be used.
Although the Rabbit can support code size approaching a megabyte, it is anticipated that the great majority of applications will use less then 250K of code, equivalent to approximately 10,000-20,000 C statements. This reflects both the compact nature of Rabbit code and the typical size of embedded applications.
Directly accessible C variables are limited to approximately 44K of memory, split between data stored in flash and RAM. This will be more than adequate for many embedded applications. Some applications may require large data arrays or tables that will require additional data memory. For this purpose Dynamic C supports a type of extended data memory that allows the use of additional data memory, even extending far beyond a megabyte.
Requirements for stack memory depend on the type of application and particularly whether preemptive multitasking is used. If preemptive multitasking is used, then each task requires its own stack. Since the stack has its own segment in 16-bit address space, it is easy to use available RAM memory to support a large number of stacks. When a preemptive change of context takes place, the STACKSEG register can be changed to map the stack segment to the portion of RAM memory that contains the stack associated with the new task that is to be run. Normally the stack segment is 4K, which is typically large enough to provide space for several (typically four) stacks. It is possible to enlarge the stack segment if stacks larger than 4K are needed. If only one stack is needed, then it is possible to eliminate the stack segment entirely and place the single stack in the data segment. This option is attractive for systems with only 32K of RAM that don't need multiple stacks.
3.3 Instruction Set Outline
"Load Immediate Data To a Register" on page 23
"Load or Store Data from or to a Constant Address" on page 23
"Load or Store Data Using an Index Register" on page 24
"Register to Register Move" on page 25
"Register Exchanges" on page 25
"Push and Pop Instructions" on page 26
"16-bit Arithmetic and Logical Ops" on page 26
"Input/Output Instructions" on page 29--these include a fix for a bug that manifests itself if an I/O instruction (prefix IOI or IOE) is followed by one of 12 single-byte op codes that use HL as an index register.In the discussion that follows, we give a few example instructions in each general category and contrast the Z80/ Z180 with the Rabbit. For a detailed description of every instruction, see Chapter 18, "Rabbit Instructions"
The Rabbit executes instructions in fewer clocks then the Z80 or Z180. The Z180 usually requires a minimum of four clocks for 1-byte opcodes or three clocks for each byte for multi-byte op codes. In addition, three clocks are required for each data byte read or written. Many instructions in the Z180 require a substantial number of additional clocks. The Rabbit usually requires two clocks for each byte of the op code and for each data byte read. Three clocks are needed for each data byte written. One additional clock is required if a memory address needs to be computed or an index register is used for addressing. Only a few instructions don't follow this pattern. An example is mul, a 16 x 16 bit signed two's complement multiply. mul is a 1-byte op code, but requires 12 clocks to execute. Compared to the Z180, not only does the Rabbit require fewer clocks, but in a typical situation it has a higher clock speed and its instructions are more powerful.
The most important instruction set improvements in the Rabbit over the Z180 are in the following areas.
- Fetching and storing data, especially 16-bit words, relative to the stack pointer or the index registers IX, IY, and HL.
- 16-bit arithmetic and logical operations, including 16-bit and's, or's, shifts and 16-bit multiply.
- Communication between the regular and alternate registers and between the index registers and the regular registers is greatly facilitated by new instructions. In the Z180 the alternate register set is difficult to use, while in the Rabbit it is well integrated with the regular register set.
- Long calls, long returns and long jumps facilitate the use of 1M of code space. This removes the need in the Z180 to utilize inefficient memory banking schemes for larger programs that exceed 64K of code.
- Input/output instructions are now accomplished by normal memory access instructions prefixed by an op code byte to indicate access to an I/O space. There are two I/O spaces, internal peripherals and external I/O devices.
Some Z80 and Z180 instructions have been deleted and are not supported by the Rabbit (see Chapter 19, "Differences Rabbit vs. Z80/Z180 Instructions"). Most of the deleted instructions are obsolete or are little-used instructions that can be emulated by several Rabbit instructions. It was necessary to remove some instructions to free up 1-byte op codes needed to implement new instructions efficiently. The instructions were not re-implemented as 2-byte op codes so as not to waste on-chip resources on unimportant instructions. Except for the instruction EX (SP),HL, the original Z180 binary encoding of op codes is retained for all Z180 instructions that are retained.
3.3.1 Load Immediate Data To a Register
A constant that follows the op code in the instruction stream can generally be loaded to any register, except PC, AF, IP and F. (Load to the PC is a jump instruction.) This includes the alternate registers on the Rabbit, but not on the Z180. Some example instructions appear below.
LD A,3
LD HL,456
LD BC',3567 ; not possible on Z180
LD H',0x4A ; not possible on Z180
LD IX,1234
LD C,54Byte loads require four clocks, word loads require six clocks. Loads to IX, IY or the alternate registers generally require two extra clocks because the op code has a 1-byte prefix.
3.3.2 Load or Store Data from or to a Constant Address
LD A,(mn) ; loads 8 bits from address mn
LD A',(mn) ; not possible on Z180
LD (mn),A
LD HL,(mn) ; load 16 bits from the address specified by mn
LD HL',(mn) ; to alternate register, not possible Z180
LD (mn),HLSimilar 16-bit loads and stores exist for DE, BC, SP, IX and IY.
It is possible to load data to the alternate registers, but it is not possible to store the data in the alternate register directly to memory.
LD A',(mn) ; allowed
** LD (mn),D' ; **** not a legal instruction!
** LD (mn),DE' ; **** not a legal instruction!3.3.3 Load or Store Data Using an Index Register
An index register is a 16-bit register, usually IX, IY, SP or HL, that is used for the address of a byte or word to be fetched from or stored to memory. Sometimes an 8-bit offset is added to the address either as a signed or unsigned number. The 8-bit offset is a byte in the instruction word. BC and DE can serve as index registers only for the special cases below.
LD A,(BC)
LD A',(BC)
LD (BC),A
LD A,(DE)
LD A',(DE)
LD (DE),AOther 8-bit loads and stores are the following.
LD r,(HL) ; r is any of 7 registers A, B, C, D, E, H, L
LD g,(HL) ; same but alternate register destination
LD (HL),r ; r is any of the 7 registers above
; or an immediate data byte
** LD (HL),g ;**** not a legal instruction!
LD r,(IX+d) ; r is any of 7 registers, d is -128 to +127 offset
LD g,(IX+d) ; same but alternate destination
LD (IX+d),r ; r is any of 7 registers or an immediate data byte
LD (IY+d),r ; IX or IY can have offset dThe following are 16-bit indexed loads and stores. None of these instructions exists on the Z180 or Z80. The only source for a store is HL. The only destination for a load is HL or HL'.
LD HL,(SP+d) ; d is an offset from 0 to 255.
; 16-bits are fetched to HL or HL'
LD (SP+d),HL ; corresponding store
LD HL,(HL+d) ; d is an offset from -128 to +127,
; uses original HL value for addressing
; l=(HL+d), h=(HL+d+1)
LD HL',(HL+d)
LD (HL+d),HL
LD (IX+d),HL ; store HL at address pointed to
; by IX plus -128 to +127 offset
LD HL,(IX+d)
LD HL',(IX+d)
LD (IY+d),HL ; store HL at address pointed to
; by IY plus -128 to +127 offset
LD HL,(IY+d)
LD HL',(IY+d)3.3.4 Register to Register Move
Any of the 8-bit registers, A, B, C, D, E, H, and L, can be moved to any other 8-bit register, for example:
LD A,c
LD d,b
LD e,lThe alternate 8-bit registers can be a destination, for example:
LD a',c
LD d',bThese instructions are unique to the Rabbit and require 2 bytes and four clocks because of the required prefix byte. Instructions such as LD A,d' or LD d',e' are not allowed.
Several 16-bit register-to-register move instructions are available. Except as noted, these instructions all require 2 bytes and four clocks. The instructions are listed below.
LD dd',BC ; where dd' is any of HL', DE', BC' (2 bytes, 4 clocks)
LD dd',DE
LD IX,HL
LD IY,HL
LD HL,IY
LD HL,IX
LD SP,HL ; 1-byte, 2 clocks
LD SP,IX
LD SP,IYOther 16-bit register moves can be constructed by using 2-byte moves.
3.3.5 Register Exchanges
Exchange instructions are very powerful because two (or more) moves are accomplished with one instruction. The following register exchange instructions are implemented.
EX af,af' ; exchange af with af'
EXX ; exchange HL, DE, BC with HL', DE', BC'
EX DE,HL ; exchange DE and HLThe following instructions are unique to the Rabbit.
EX DE',HL ; 1 byte, 2 clocks
EX DE, HL' ; 2 bytes, 4 clocks
EX DE', HL' ; 2 bytes, 4 clocksThe following special instructions (Rabbit and Z180/Z80) exchange the 16-bit word on the top of the stack with the HL, the IX, or the IY register. These three instructions are each 2 bytes and 15 clocks.
EX (SP),HL
EX (SP),IX
EX (SP),IY3.3.6 Push and Pop Instructions
There are instructions to push and pop the 16-bit registers AF, HL, DC, BC, IX, and IY. The registers AF', HL', DE', and BC' can be popped. Popping the alternate registers is exclusive to the Rabbit, and is not allowed on the Z80 / Z180.
POP HL
PUSH BC
PUSH IX
PUSH af
POP DE
POP DE'
POP HL'3.3.7 16-bit Arithmetic and Logical Ops
The HL register is the primary 16-bit accumulator. IX and IY can serve as alternate accumulators for many 16-bit operations. The Z180/Z80 has a weak set of 16-bit operations, and as a practical matter the programmer has to resort to combinations of 8-bit operations in order to perform many 16-bit operations. The Rabbit has many new op codes for 16-bit operations, removing some of this weakness.
The basic Z80/Z180 16-bit arithmetic instructions are
ADD HL,ww ; where ww is HL, DE, BC, SP
ADC HL,ww ; ADD and ADD carry
SBC HL,ww ; sub and sub carry
INC ww ; increment the register (without affecting flags)In the above op codes, IX or IY can be substituted for HL. The
ADDandADCinstructions can be used to left-shift HL with the carry. An alternate destination prefix (ALTD) may be used on the above instructions. This causes the result and its flags to be stored in the corresponding alternate register. If theALTDflag is used when IX or IY is the destination register, then only the flags are stored in the alternate flag register.The following new instructions have been added for the Rabbit.
;Shifts
RR HL ; rotate HL right with carry, 1 byte, 2 clocks
; note use ADC HL,HL for left rotate, or add HL,HL if
; no carry in is needed.
RR DE ; 1 byte, 2 clocks
RL DE ; rotate DE left with carry, 1-byte, 2 clocks
RR IX ; rotate IX right with carry, 2 bytes, 4 clocks
RR IY ; rotate IY right with carry
;Logical Operations
AND HL,DE ; 1 byte, 2 clocks
AND IX,DE ; 2 bytes, 4 clocks
AND IY,DE
OR HL,DE ; 1 byte, 2 clocks
OR IX,DE ; 2 bytes, 4 clocks
OR IY,DEThe
BOOLinstruction is a special instruction designed to help test the HL register.BOOLsets HL to the value 1 if HL is non zero, otherwise, if HL is zero its value is not changed. The flags are set according to the result.BOOLcan also operate on IX and IY.
BOOL HL ; set HL to 1 if non- zero, set flags to match HL
BOOL IX
BOOL IY
ALTD BOOL HL ; set HL' an f' according to HL
ALTD BOOL IY ; modify IY and set f' with flags of resultThe
SBCinstruction can be used in conjunction with theBOOLinstruction for performing comparisions. TheSBCinstruction subtracts one register from another and also subtracts the carry bit. The carry out is inverted compared to the carry that would be expected if the number subtracted was negated and added. The following examples illustrate the use of theSBCandBOOLinstructions.
; Test if HL>=DE - HL and DE unsigned numbers 0-65535
OR a ; clear carry
SBC HL,DE ; if C==0 then HL>=DE else if C==1 then HL<DE
; convert the carry bit into a boolean variable in HL
;
SBC HL,HL ; sets HL==0 if C==0, sets HL==0x0ffff if C==1
BOOL HL ; HL==1 if C was set, otherwise HL==0
;
; convert not carry bit into boolean variable in HL
SBC HL,HL ; HL==0 if C==0 else HL==ffff if C=1
INC HL ; HL==1 if C==0 else HL==0 if C==1
; note carry flag set, but zero / sign flags reversedIn order to compare signed numbers using the
SBCinstruction, the programmer can map the numbers into an equivalent set of unsigned numbers by inverting the sign bit of each number before performing the comparison. This maps the most negative number 0x08000 to the smallest unsigned number 0x0000, and the most positive signed number 0x07FFF to the largest unsigned number 0x0FFFF. Once the numbers have been converted, the comparision can be done as for unsigned numbers. This procedure is faster than using a jump tree that requires testing the sign and overflow bits.
; example - test for HL>=DE where HL and DE are signed numbers
; invert sign bits on both
ADD HL,HL ; shift left
CCF ; invert carry
RR HL ; rotate right
RL DE
CCF
RR DE ; invert DE sign
SBC HL,DE ; no carry if HL>=DE
; generate boolean variable true if HL>=DE
SBC HL,HL ; zero if no carry else -1
INC HL ; 1 if no carry, else zero
BOOL ; use this instruction to set flags if neededThe SBC instruction can also be used to perform a sign extension.
; extend sign of l to HL
LD A,l
rla ; sign to carry
SBC A,a ; a is all 1's if sign negative
LD h,a ; sign extendedThe multiply instruction performs a signed multiply that generates a 32-bit signed result.
MUL ; signed multiply of BC and DE,
; result in HL:BC - 1 byte, 12 clocksIf a 16-bit by 16-bit multiply with a 16-bit result is performed, then only the low part of the 32-bit result (
BC) is used. This (counter intuitively) is the correct answer whether the terms are signed or unsigned integers. The following method can be used to perform a 16 x 16 bit multiply of two unsigned integers and get an unsigned 32-bit result. This uses the fact that if a negative number is multiplied the sign causes the other multiplier to be subtracted from the product. The method shown below adds double the number subtracted so that the effect is reversed and the sign bit is treated as a positive bit that causes an addition.
LD BC,n1
LD HL',BC ; save BC in HL'
LD DE,n2
LD A,b ; save sign of BC
MUL ; form product in HL:BC
OR a ; test sign of BC multiplier
JR p,x1 ; if plus continue
ADD HL,DE ; adjust for negative sign in BC
x1:
RL DE ; test sign of DE
JR nc,x2 ; if not negative
; subtract other multiplier from HL
EX DE,HL'
ADD HL,DE
x2:
; final unsigned 32 bit result in HL:BCThis method can be modified to multiply a signed number by an unsigned number. In that case only the unsigned number has to be tested to see if the sign is on, and in that case the signed number is added to the upper part of the product.
The multiply instruction can also be used to perform left or right shifts. A left shift of n positions can be accomplished by multiplying by the unsigned number 2^^n. This works for n # 15, and it doesn't matter if the numbers are signed or unsigned. In order to do a right shift by n (0 < n < 16), the number should be multiplied by the unsigned number 2^^(16 - n), and the upper part of the product taken. If the number is signed, then a signed by unsigned multiply must be performed. If the number is unsigned or is to be treated as unsigned for a logical right shift, then an unsigned by unsigned multiply must be performed. The problem can be simplified by excluding the case where the multiplier is 2^^15.
3.3.8 Input/Output Instructions
The Rabbit uses an entirely different scheme for accessing input/output devices. Any memory access instruction may be prefixed by one of two prefixes, one for internal I/O space and one for external I/O space. When so prefixed, the memory instruction is turned into an I/O instruction that accesses that I/O space at the I/O address specified by the 16-bit memory address used. For example
IOI LD A,(0x85) ; loads A register with contents
; of internal I/O register at location 0x85.
LD IY,0x4000
IOE LD HL,(IY+5) ; get word from external I/O location 0x4005By using the prefix approach, all the 16-bit memory access instructions are available for reading and writing I/O locations. The memory mapping is bypassed when I/O operations are executed.
I/O writes to the internal I/O registers require only two clocks, rather than the minimum of three clocks required for writes to memory or external I/O devices.
In certain conditions where an I/O operation is followed by a special one-byte instruction, a bug in the original Rabbit 2000 chip causes an I/O access to take place instead of a memory access operation. The problem was corrected in revisions A-C of the Rabbit 2000. (Refer to Appendix B for further information to determine which version of the Rabbit 2000 chip you are using.)
The bug is manifested if an I/O instruction (prefix
IOIorIOE) is followed by one of 12 single-byte op codes that use HL as an index register. The 12 instructions are:
ADC A,(HL)
ADD A, (HL)
AND (HL)
CP (HL)
OR (HL)
SBC A,(HL)
SUB (HL)
XOR (HL)
DEC (HL)
INC (HL)
LD r,(HL)
LD (HL),r
where
r, an 8-byte register, is one ofA,B,C,D,E,H, orL.The only combination that is very likely to occur in user written assembly language programs is an I/O instruction followed by
LD (HL),r.The nature of the failure is that the memory address translation does not take place and so the appropriate memory chip select will not be enabled for the second instruction. In the case of external I/O operations where the I/O strobes on Port E may be enabled, an I/O "chip select" (I/O strobe) will take place instead of a memory chip select. If one of the above instructions follows an internal I/O operation and the memory access takes place in the base region where address translation does not take place, the memory operation will take place properly because the appropriate memory chip select is enabled for internal I/O operations.
The bug may be easily avoided by placing a
NOPbetween the I/O instruction and a following instruction from the above list.Rabbit users are unlikely to encounter this problem because the sequence of instructions that exhibit the bug is never generated by the Dynamic C compiler or in any of the standard libraries.
Beginning with the 6.57 release, the Dynamic C compiler and assembler will correct for this anomaly by inserting
NOPswhere necessary in generated code.3.4 How to Do It in Assembly Language--Tips and Tricks
3.4.1 Zero HL in 4 Clocks
BOOL HL ; 2 clocks, clears carry, HL is 1 or 0
RR HL ; 2 clocks, 4 total - get rid of possible 1This sequence requires four clocks compared to six clocks for
LD HL,0.3.4.2 Exchanges Not Directly Implemented
EX DE',HL ; 2 clocks
EX DE',HL' ; 4 clocks
EX DE',HL ; 2 clocks, 8 total
EX DE',HL ; 2 clocks
EX DE,HL ; 2 clocks
EX DE',HL ; 2 clocks, 6 total
EX DE',HL ; 2 clocks
EX DE,HL' ; 4
EX DE,HL ; 2
EXX ; 2
EX DE,HL ; 2Move between IX, IY and DE, DE'
;IX, IX --> DE
EX DE,HL
LD HL,IX/IY / LD IX/IY,HL
EX DE,HL ; 8 clocks total
; DE --> IX/ IY
EX DE,HL
LD IX/IY,HL
EX DE,HL ; 8 clocks total3.4.3 Manipulation of Boolean Variables
Logical operations involving HL when HL is a logical variable with a value of 1 or 0--this is important for the C language where the least bit of a 16-bit integer is used to represent a logical result
Logical
notoperator--invert bit 0 of HL in four clocks (also works forIX,IYin eight clocks)
DEC HL ; 1 goes to zero, zero goes to -1
BOOL HL ; -1 to 1, zero to zero. 4 clocks totalLogical
xoroperator--xor HL,DE when HL/DE are 1 or 0.
ADD HL,DE
RES 1,l ; 6 clocks total, clear bit 1 result of if 1+1=23.4.4 Comparisons of Integers
Unsigned integers may be compared by testing the zero and carry flags after a subtract operation. The zero flag is set if the numbers are equal. With the SBC instruction the carry cleared is set if the number subtracted is less than or equal to the number it is subtracted from. 8-bit unsigned integers span the range 0-255. 16-bit unsigned integers span the range 0-65535.
OR a ; clear carry
SBC HL,DE ; HL=A and DE=B
A>=B !C
A<B C
A==B Z
A>B !C & !Z
A<=B C v ZIf A is in HL and B is in DE these operations can be performed as follows assuming that the object is to set HL to 1 or 0 depending on whether the compare is true or false.
; compute HL<DE
; unsigned integers
; EX DE,HL ; uncomment for DE<HL
OR a ; clear carry
SBC HL,DE ; C set if HL<DE
SBC HL,HL ; HL-HL-C -- -1 if carry set
BOOL HL ; set to 1 if carry, else zero
; else result == 0
;unsigned integers
; compute HL>=DE or DE>=HL - check for !C
; EX DE,HL ; uncomment for DE<=HL
OR a ; clear carry
SBC HL,DE ; !C if HL>=DE
SBC HL,HL ; HL-HL-C - zero if no carry, -1 if C
INC HL ; 14 / 16 clocks total -if C after first SBC result 1,
; else 0
; 0 if C , 1 if !C
;
: compute HL==DE
OR a ; clear carry
SBC HL,DE ; zero is equal
BOOL HL ; force to zero, 1
DEC HL ; invert logic
BOOL HL ; 12 clocks total -logical not, 1 for inputs equal
;Some simplifications are possible if one of the unsigned numbers being compared is a constant. Note that the carry has a reverse sense from
SBC. In the following examples, the pseudo-code in the formLD DE,(65535-B)does not indicate a load ofDEwith the address pointed to by65535-B, but simply indicates the difference between 65535 and the 16-bit unsigned integerB.
;test for HL>B B is constant
LD DE,(65535-B)
ADD HL,DE ; carry set if HL>B
SBC HL,HL ; HL-HL-C - result -1 if carry set, else zero
BOOL HL ; 14 total clocks - true if HL>B
; HL>=B B is constant not zero
LD DE,(65536-B)
ADD HL,DE
SBC HL,HL
BOOL HL ; 14 clocks
; HL>=B and B is zero
LD HL,1 ; 6 clocks
; HL<B B is a constant, not zero (if B==0 always false)
LD DE,(65536-B)
ADD HL,DE ; not carry if HL<B
SBC HL,HL ; -1 if carry, else 0
INC HL ; 14 clocks --0 if carry, else 1 if no carry
;
; HL <= B B is constant not zero
LD DE,(65535-B)
ADD HL,DE ; ~C if HL<=B
CCF ; C if true
SBC HL,HL ; if C -1 else 0
INC HL ; 16 clocks -- 1 if true, else 0
;
; HL <= B B is zero - true if HL==0
BOOL HL ; result in HL
;
; HL==B and B is a constant not zero
LD DE,(65536-B)
ADD HL,DE ; zero if equal
BOOL HL
INC HL
RES 1,l ; 16 clocks
; HL==B and B==0
BOOL HL
INC HL
RES 1,l ; 8 clocksFor signed integers the conventional method to look at the zero flag, the minus flag and the overflow flag. Signed 8-bit integers span the range -128 to +127 (0x80 to 0x7F). Signed 16-bit integers span the range -32768 to + 32767 (0x8000 to 0x7FFF). The sign and zero flag tell which is the larger number after the subtraction unless the overflow is set, in which case the sign flag needs to be inverted in the logic, that is, it is wrong.
A>B (!S & !V & !Z) v (S & V)
A<B (S & !V) v (!S & V & !Z)
A==B
A>=B
A<=BAnother method of doing signed compare is to first map the signed integers onto unsigned integers by inverting bit 15. This is shown in Figure 3-7 on page 34. Once the mapping has been performed by inverting bit 15 on both numbers, the comparisions can be done as if the numbers were unsigned integers. This avoids having to construct a jump tree to test the overflow and sign flags. An example is shown below.
; test HL>5 for signed integers
LD DE,65535-(5+0x08000) ; 5 mapped to unsigned integers
LD BC,0x08000
ADD HL,BC ; invert high bit
ADD HL,DE ; 16 clocks to here
; carry now set if HL>5 - opportunity to jump on carry
SUBC HL,HL ; HL-HL-C ; if C on result is -1, else zero
BOOL HL ; 22 clocks total - true if HL>5 else false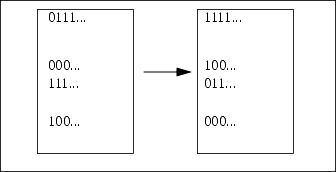
3.4.5 Atomic Moves from Memory to I/O Space
To avoid disabling interrupts while copying a shadow register to its target register, it is desirable to have an atomic move from memory to I/O space. This can be done using LDD or LDI instructions.
LD HL,sh_PDDDR ; point to shadow register
LD DE,PDDDR ; set DE to point to I/O reg
SET 5,(HL) ; set bit 5 of shadow register
; use ldd instruction for atomic transfer
IOI ldd ; (io DE)<-(HL) HL--, DE--When the
LDDinstruction is prefixed with an I/O prefix, the destination becomes the I/O address specified by DE. The decrementing of HL and DE is a side effect. If the repeating instructionsLDIRandLDDRare used, interrupts can take place between successive iterations. Word stores to I/O space can be used to set two I/O registers at adjacent addresses with a single noninterruptable instruction.3.5 Interrupt Structure
When an interrupt occurs on the Rabbit, the return address is pushed on the stack, and control is transferred to the address of the interrupt service routine. The address of the interrupt service routine has two parts: the upper byte of the address comes from a special register and the lower byte is fixed by hardware for each interrupt, as shown in Table 7-11. There are separate registers for internal interrupts (IIR) and external interrupts (EIR) to specify the high byte of the interrupt service routine address. These registers are accessed by special instructions.
LD A,IIR
LD IIR,A
LD A,EIR
LD EIR,AInterrupts are initiated by hardware devices or by certain 1-byte instructions called reset instructions.
RST 10
RST 18
RST 20
RST 28
RST 38The RST instructions are similar to those on the Z80 and Z180, but certain ones have been removed from the instruction set (00, 08, 30). The
RSTinterrupts are not inhibited regardless of the processor priority. The user is advised to exercise caution when using these instructions as they are mostly reserved for the use of Dynamic C for debugging. Unlike the Z80 or Z180, the IIR register contributes the upper byte of the service routine address for RST interrupts.Since interrupt routines do not affect the XPC, interrupt routines must be located in the root code space. However, they can jump to the extended code space after saving the XPC on the stack.
3.5.1 Interrupt Priority
The Z80 and Z180 have two levels of interrupt priority: maskable and nonmaskable. The nonmaskable interrupt cannot be disabled and has a fixed interrupt service routine address of 0x66. The Rabbit, in contrast, has three levels of interrupt priority and four priority levels at which the processor can operate. If an interrupt is requested, and the priority of the interrupt is higher than that of the processor, the interrupt will take place after the execution of the current instruction is complete (except for privileged instructions).
Multiple interrupt priorities have been established to make it feasible for the embedded systems programmer to have extremely fast interrupts available. Interrupt latency refers to the time required for an interrupt to take place after it has been requested. Generally, interrupts of the same priority are disabled when an interrupt service routine is entered. Sometimes interrupts must stay disabled until the interrupt service routine is completed, other times the interrupts can be re-enabled once the interrupt service routine has at least disabled its own cause of interrupt. In any case, if several interrupt routines are operating at the same priority, this introduces interrupt latency while the next routine is waiting for the previous routine to allow more interrupts to take place. If a number of devices have interrupt service routines, and all interrupts are of the same priority, then pending interrupts can not take place until at least the interrupt service routine in progress is finished, or at least until it changes the interrupt priority. As a rule of thumb, Rabbit Semiconductor usually suggests that 100 µs be allowed for interrupt latency on Z180-based controllers. This can result if, for example, there are five active interrupt routines, and each turns off the interrupts for at most 20 µs.
The intention in the Rabbit is that most interrupting devices will use priority 1 level interrupts. Devices that need extremely fast response to interrupts will use priority level 2 or 3 interrupts. Since code that runs at priority level 0 or 1 never disables level 2 and level 3 interrupts, these interrupts will take place within about 20 clocks, the length of the longest instruction or longest sensible sequence of privileged instructions followed by an unprivileged instruction. It is important that the user be careful not to overdisable interrupts in critical code sections. The processor priority should not be raised above level 1 except in carefully considered situations.
The effect of the processor priority on interrupts is shown in Table 3-1. The priority of the interrupt is usually established by bits in an I/O control register associated with the hardware that creates the interrupt. The 8-bit interrupt register (IP) holds the processor priority in the least significant 2 bits. When an interrupt takes place, the IP register is shifted left 2 positions and the lower 2 bits are set to equal the priority of the interrupt that just took place. This means that an interrupt service request (ISR) can only be interrupted by an interrupt of higher priority (unless the priority is explicitly set lower by the programmer). The IP register serves as a 4-word stack of 2-bit words to save and restore interrupt priorities. It can be shifted right, restoring the previous priority by a special instruction (
IPRES). Since only the current processor priority and 3 previous priorities can be saved in the interrupt register, instructions are also provided toPUSHandPOP IPusing the regular stack. A new priority can be "pushed" into the IP register with special instructions (IPSET 0,IPSET 1,IPSET 2,IPSET 3).
3.5.2 Multiple External Interrupting Devices
The Rabbit has two distinct external interrupt request lines. If there are more than two external causes of interrupts, then these lines must be shared between multiple devices. The interrupt line is edge sensitive, meaning that it requests an interrupt only when a rising or falling edge, whichever is specified in the setup registers, takes place. The state of the interrupt line(s) can always be read by reading parallel port E since they share pins with parallel port E.
If several lines are to share interrupts with the same port, the individual interrupt requests would normally be or'ed together so that any device can cause an interrupt. If several devices are requesting an interrupt at the same time, only one interrupt results because there will be only one transition of the interrupt request line. To resolve the situation and make sure that the separate interrupt routines for the different devices are called, a good method is to have a interrupt dispatcher in software that is aided by providing separate attention request lines for each device. The attention request lines are basically the interrupt request lines for the separate devices before they are or'ed together. The interrupt dispatcher calls the interrupt routines for all devices requesting interrupts in priority order so that all interrupts are serviced.
3.5.3 Privileged Instructions, Critical Sections and Semaphores
Normally an interrupt happens at the end of the instruction currently executing. However, if the instruction executing is privileged, the interrupt cannot take place at the end of the instruction and is deferred until a non privileged instruction is executed, usually the next instruction. Privileged instructions are provided as a handy way of making a certain operation atomic because there would be a software problem if an interrupt took place after the instruction. Turning off the interrupts explicitly may be too time consuming or not possible because the purpose of the privileged instruction is to manipulate the interrupt controls. For additional information on privileged instructions, see Section 18.19, "Privileged Instructions"
The privileged instructions to load the stack are listed below.
LD SP,HL
LD SP,IY
LD SP,IXThe following instructions to load SP are privileged because they are frequently followed by an instruction to change the stack segment register. If an interrupt occurs between these two instructions and the following instruction, the stack will be ill-defined.
LD SP,HL
IOI LD sseg,aThe privileged instructions to manipulate the IP register are listed below.
IPSET 0 ; shift IP left and set priority 00 in bits 1,0
IPSET 1
IPSET 2
IPSET 3
IPRES ; rotate IP right 2 bits, restoring previous priority
RETI ; pops IP from stack and then pops return address
POP IP ; pop IP register from stack3.5.4 Critical Sections
Certain library routines may need to disable interrupts during a critical section of code. Generally these routines are only legal to call if the processor priority is either 0 or 1. A priority higher than this implies custom hand-coded assembly routines that do not call general-purpose libraries. The following code can be used to disable priority 1 interrupts.
IPSET 1 ; save previous priority and set priority to 1
....critical section...
IPRES ; restore previous priorityThis code is safe if it is known that the code in the critical section does not have an embedded critical section. If this code is nested, there is the danger of overflowing the IP register. A different version that can be nested is the following.
PUSH IP
IPSET 1 ; save previous priority and set priority to 1
....critical section...
POP IP ; restore previous priorityThe following instructions are also privileged.
LD A,xpc
LD xpc,a
BIT B,(HL)3.5.5 Semaphores Using Bit B,(HL)
The bit B,(HL) instruction is privileged to allow the construction of a semaphore by the following code.
BIT B,(HL) ; test a bit in the byte at (HL)
SET B,(HL) ; make sure bit set, does not affect flag
; if zero flag set the semaphore belongs to us;
; otherwise someone else has itA semaphore is used to gain control of a resource that can only belong to one task or program at a time. This is done by testing a bit to see if it is on, in which case someone else is using the resource, otherwise setting the bit to indicate ownership of the resource. No interrupt can be allowed between the test of the bit and the setting of the bit as this might allow two different program to both think they own the resource.
3.5.6 Computed Long Calls and Jumps
The instruction to set the XPC is privileged to so that a computed long call or jump can be made. This would be done by the following sequence.
LD xpc,a
JP (HL)In this case, A has the new XPC, and HL has the new PC. This code should normally be executed in the root segment so as not to pull the memory out from under the JP (HL) instruction.
A call to a computed address can be performed by the following code.
; A=xpc, IY=address
;
LD A,newxpc
LD IY,newaddress
LCALL DOCALL ; call utility routine in the root
;
; The DOCALL routine
DOCALL:
LD xpc,a ; SET xpc
JP (IY) ; go to the routine
| Rabbit Semiconductor www.rabbit.com |